2024
Accelerated Motion Correction with Deep Generative Diffusion Models
Brett Levac, Siddharth Kumar, Ajil Jalal, Jon Tamir
Magnetic Resonance in Medicine 2024
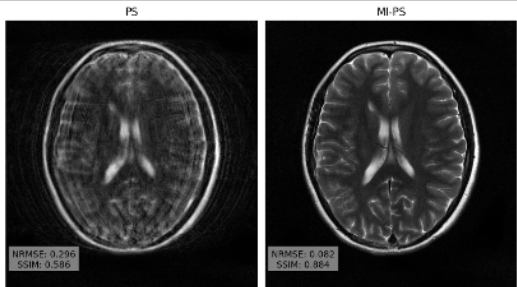
Magnetic Resonance Imaging (MRI) is a powerful medical imaging modality, but unfortunately suffers from long scan times which, aside from increasing operational costs, can lead to image artifacts due to patient motion. Motion during the acquisition leads to inconsistencies in measured data that manifest as blurring and ghosting if unaccounted for in the image reconstruction process. Various deep learning based reconstruction techniques have been proposed which decrease scan time by reducing the number of measurements needed for a high fidelity reconstructed image. Additionally, deep learning has been used to correct motion using end-to-end techniques. This, however, increases susceptibility to distribution shifts at test time (sampling pattern, motion level). In this work we propose a framework for jointly reconstructing highly sub-sampled MRI data while estimating patient motion using score-based generative models. Our method does not make specific assumptions on the sampling trajectory or motion pattern at training time and thus can be flexibly applied to various types of measurement models and patient motion. We demonstrate our framework on retrospectively accelerated 2D brain MRI corrupted by rigid motion.
Diffusion posterior sampling is computationally intractable
Shivam Gupta, Ajil Jalal, Aditya Parulekar, Eric Price, Zhiyang Xun
International Conference on Machine Learning (ICML) 2024
Diffusion models are a remarkably effective way of learning and sampling from a distribution p(x). In posterior sampling, one is also given a measurement model p(y | x) and a measurement y, and would like to sample from p(x | y). Posterior sampling is useful for tasks such as inpainting, super-resolution, and MRI reconstruction, so a number of recent works have given algorithms to heuristically approximate it; but none are known to converge to the correct distribution in polynomial time. In this paper we show that posterior sampling is computationally intractable: under the most basic assumption in cryptography—that one-way functions exist—there are instances for which every algorithm takes superpolynomial time, even though unconditional sampling is provably fast. We also show that the exponential-time rejection sampling algorithm is essentially optimal under the stronger plausible assumption that there are one-way functions that take exponential time to invert.
Learning a 1-layer conditional generative model in total variation
Ajil Jalal, Justin Kang, Ananya Uppal, Kannan Ramchandran, Eric Price
Advances in Neural Information Processing Systems (NeurIPS) 2024
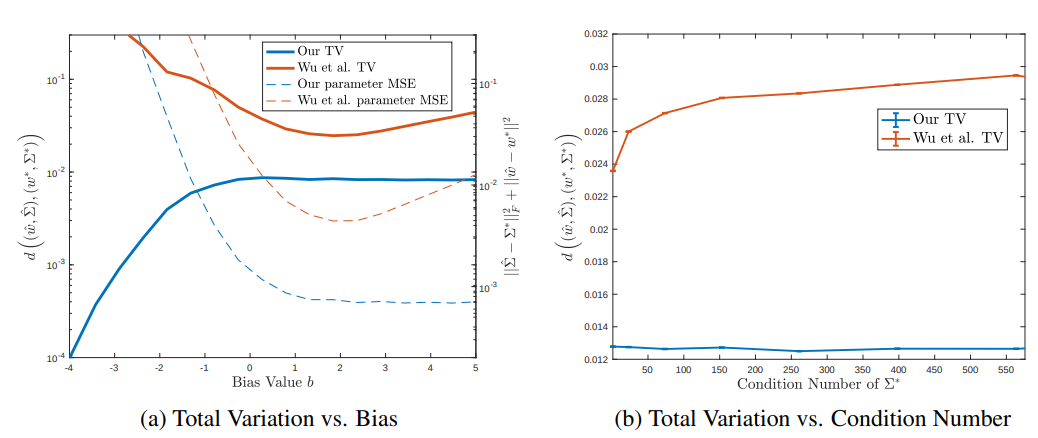
A conditional generative model is a method for sampling from a conditional distribution p(y | x). For example, one may want to sample an image of a cat given the label “cat”. A feed-forward conditional generative model is a function g(x, z) that takes the input x and a random seed z, and outputs a sample y from p(y | x). Ideally the distribution of outputs (x, g(x, z)) would be close in total variation to the ideal distribution (x, y). Generalization bounds for other learning models require assumptions on the distribution of x, even in simple settings like linear regression with Gaussian noise. We show these assumptions are unnecessary in our model, for both linear regression and single-layer ReLU networks. Given samples (x, y), we show how to learn a 1-layer ReLU conditional generative model in total variation. As our result has no assumption on the distribution of inputs x, if we are given access to the internal activations of a deep generative model, we can compose our 1-layer guarantee to progressively learn the deep model using a near-linear number of samples.
2023
MRI reconstruction with side information using diffusion models
Brett Levac, Ajil Jalal, Kannan Ramchandran, Jon Tamir
57th Asilomar Conference on Signals, Systems, and Computers 2023
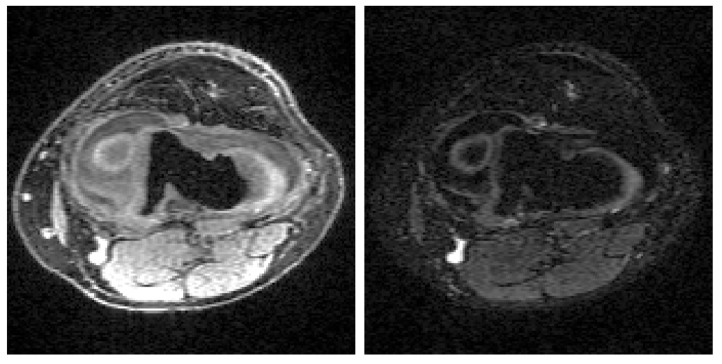
Magnetic resonance imaging (MRI) exam protocols consist of multiple contrast-weighted images of the same anatomy to emphasize different tissue properties. Due to the long acquisition times required to collect fully sampled k-space measurements, it is common to only collect a fraction of k-space for each scan and subsequently solve independent inverse problems for each image contrast. Recently, there has been a push to further accelerate MRI exams using data-driven priors, and generative models in particular, to regularize the ill-posed inverse problem of image reconstruction. These methods have shown promising improvements over classical methods. However, many of the approaches neglect the additional information present in a clinical MRI exam like the multi-contrast nature of the data and treat each scan as an independent reconstruction. In this work we show that by learning a joint Bayesian prior over multi-contrast data with a score-based generative model we are able to leverage the underlying structure between random variables related to a given imaging problem. This leads to an improvement in image reconstruction fidelity over generative models that rely only on a marginal prior over the image contrast of interest.
Accelerated motion correction for MRI using score-based generative models
Brett Levac, Ajil Jalal, Jon Tamir
2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI) 2023
Magnetic Resonance Imaging (MRI) is a powerful medical imaging modality, but unfortunately suffers from long scan times which, aside from increasing operational costs, can lead to image artifacts due to patient motion. Motion during the acquisition leads to inconsistencies in measured data that manifest as blurring and ghosting if unaccounted for in the image reconstruction process. Various deep learning based reconstruction techniques have been proposed which decrease scan time by reducing the number of measurements needed for a high fidelity reconstructed image. Additionally, deep learning has been used to correct motion using end-to-end techniques. This, however, increases susceptibility to distribution shifts at test time (sampling pattern, motion level). In this work we propose a framework for jointly reconstructing highly sub-sampled MRI data while estimating patient motion using score-based generative models. Our method does not make specific assumptions on the sampling trajectory or motion pattern at training time and thus can be flexibly applied to various types of measurement models and patient motion. We demonstrate our framework on retrospectively accelerated 2D brain MRI corrupted by rigid motion.
2021
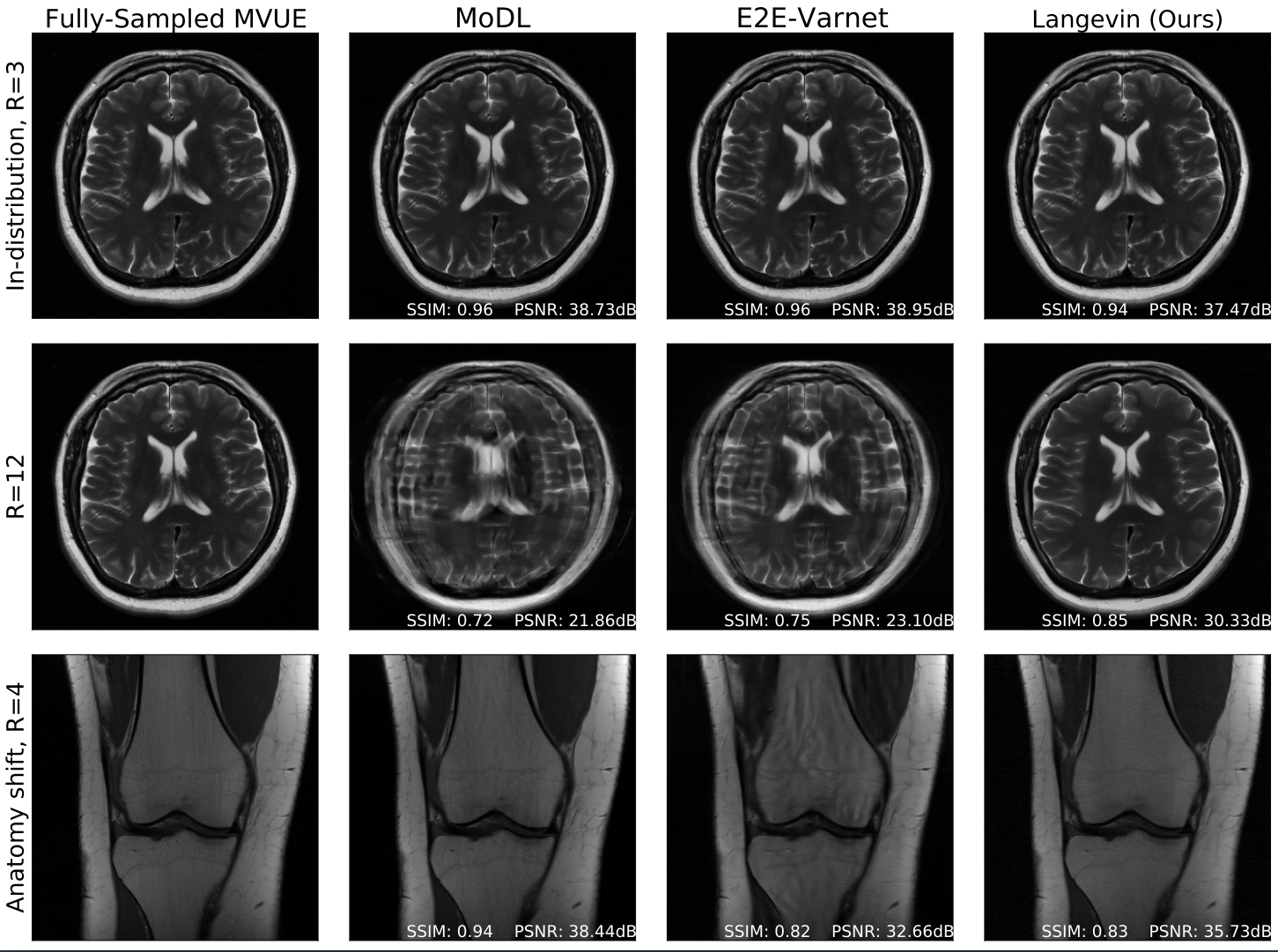
Robust compressed sensing MRI with deep generative priors
Ajil Jalal, Marius Arvinte, Giannis Daras, Eric Price, Alex Dimakis, Jon Tamir
Thirty-Fifth Conference on Neural Information Processing Systems (NeurIPS) 2021
The CSGM framework (Bora-Jalal-Price-Dimakis' 17) has shown that deep generative priors can be powerful tools for solving inverse problems. However, to date this framework has been empirically successful only on certain datasets (for example, human faces and MNIST digits), and it is known to perform poorly on out-of-distribution samples. In this paper, we present the first successful application of the CSGM framework on clinical MRI data. We train a generative prior on brain scans from the fastMRI dataset, and show that posterior sampling via Langevin dynamics achieves high quality reconstructions. Furthermore, our experiments and theory show that posterior sampling is robust to changes in the ground-truth distribution and measurement process.

Fairness for image generation with uncertain sensitive attributes
Ajil Jalal, Sushrut Karmalkar, Jessica Hoffmann, Alex Dimakis, Eric Price
International Conference on Machine Learning (ICML) 2021
This work tackles the issue of fairness in the context of generative procedures, such as image super-resolution, which entail different definitions from the standard classification setting. Moreover, while traditional group fairness definitions are typically defined with respect to specified protected groups–camouflaging the fact that these groupings are artificial and carry historical and political motivations–we emphasize that there are no ground truth identities. For instance, should South and East Asians be viewed as a single group or separate groups? Should we consider one race as a whole or further split by gender? Choosing which groups are valid and who belongs in them is an impossible dilemma and being “fair” with respect to Asians may require being “unfair” with respect to South Asians. This motivates the introduction of definitions that allow algorithms to be oblivious to the relevant groupings. We define several intuitive notions of group fairness and study their incompatibilities and trade-offs. We show that the natural extension of demographic parity is strongly dependent on the grouping, and impossible to achieve obliviously. On the other hand, the conceptually new definition we introduce, Conditional Proportional Representation, can be achieved obliviously through Posterior Sampling. Our experiments validate our theoretical results and achieve fair image reconstruction using state-of-the-art generative models.

Instance-Optimal Compressed Sensing via Posterior Sampling
Ajil Jalal, Sushrut Karmalkar, Alex Dimakis, Eric Price
International Conference on Machine Learning (ICML) 2021
We characterize the measurement complexity of compressed sensing of signals drawn from a known prior distribution, even when the support of the prior is the entire space (rather than, say, sparse vectors). We show for Gaussian measurements and any prior distribution on the signal, that the posterior sampling estimator achieves near-optimal recovery guarantees. Moreover, this result is robust to model mismatch, as long as the distribution estimate (e.g., from an invertible generative model) is close to the true distribution in Wasserstein distance. We implement the posterior sampling estimator for deep generative priors using Langevin dynamics, and empirically find that it produces accurate estimates with more diversity than MAP.

Intermediate layer optimization for inverse problems using deep generative models
Giannis Daras, Joseph Dean, Ajil Jalal, Alex Dimakis
International Conference on Machine Learning (ICML) 2021
We propose Intermediate Layer Optimization (ILO), a novel optimization algorithm for solving inverse problems with deep generative models. Instead of optimizing only over the initial latent code, we progressively change the input layer obtaining successively more expressive generators. To explore the higher dimensional spaces, our method searches for latent codes that lie within a small ball around the manifold induced by the previous layer. Our theoretical analysis shows that by keeping the radius of the ball relatively small, we can improve the established error bound for compressed sensing with deep generative models. We empirically show that our approach outperforms state-of-the-art methods introduced in StyleGAN-2 and PULSE for a wide range of inverse problems including inpainting, denoising, super-resolution and compressed sensing.
2020

Robust compressed sensing using generative models
Ajil Jalal, Liu Liu, Alex Dimakis, Constantine Caramanis
Thirty-Third Conference on Neural Information Processing Systems (NeurIPS) 2020
We consider estimating a high dimensional signal in $\R^ n $ using a sublinear number of linear measurements. In analogy to classical compressed sensing, here we assume a generative model as a prior, that is, we assume the signal is represented by a deep generative model $ G:\R^ k\rightarrow\R^ n $. Classical recovery approaches such as empirical risk minimization (ERM) are guaranteed to succeed when the measurement matrix is sub-Gaussian. However, when the measurement matrix and measurements are heavy tailed or have outliers, recovery may fail dramatically. In this paper we propose an algorithm inspired by the Median-of-Means (MOM). Our algorithm guarantees recovery for heavy tailed data, even in the presence of outliers. Theoretically, our results show our novel MOM-based algorithm enjoys the same sample complexity guarantees as ERM under sub-Gaussian assumptions. Our experiments validate both aspects of our claims: other algorithms are indeed fragile and fail under heavy tailed and/or corrupted data, while our approach exhibits the predicted robustness.
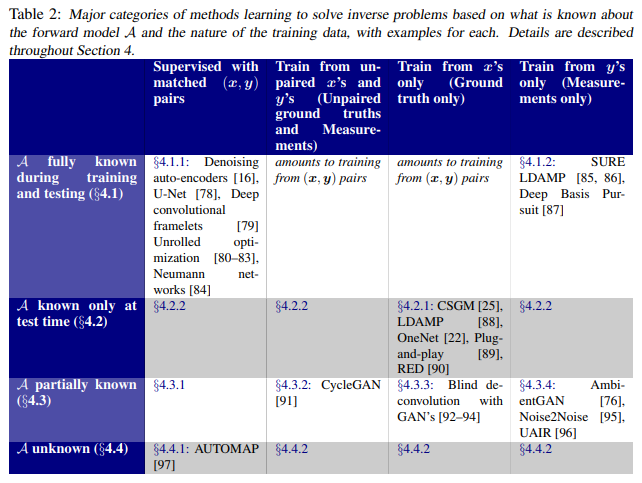
Deep learning techniques for inverse problems in imaging
Greg Ongie, Ajil Jalal, Chris Metzler, Richard Baraniuk, Alex Dimakis, Rebecca Willet
IEEE Journal on Selected Areas in Information Theory 2020
Recent work in machine learning shows that deep neural networks can be used to solve a wide variety of inverse problems arising in computational imaging. We explore the central prevailing themes of this emerging area and present a taxonomy that can be used to categorize different problems and reconstruction methods. Our taxonomy is organized along two central axes: (1) whether or not a forward model is known and to what extent it is used in training and testing, and (2) whether or not the learning is supervised or unsupervised, i.e., whether or not the training relies on access to matched ground truth image and measurement pairs. We also discuss the tradeoffs associated with these different reconstruction approaches, caveats and common failure modes, plus open problems and avenues for future work.
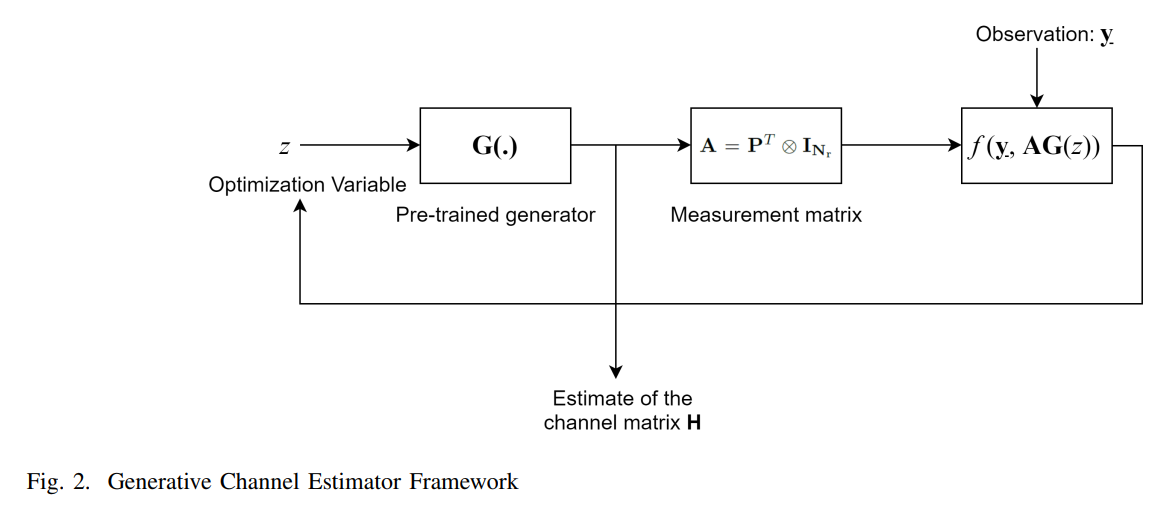
High dimensional channel estimation using deep generative networks
Eren Balevi, Akash Doshi, Ajil Jalal, Alex Dimakis, Jeff Andrews
IEEE Journal on Selected Areas in Communications (JSAC) 2020
This paper presents a novel compressed sensing (CS) approach to high dimensional wireless channel estimation by optimizing the input to a deep generative network. Channel estimation using generative networks relies on the assumption that the reconstructed channel lies in the range of a generative model. Channel reconstruction using generative priors outperforms conventional CS techniques and requires fewer pilots. It also eliminates the need of a priori knowledge of the sparsifying basis, instead using the structure captured by the deep generative model as a prior. Using this prior, we also perform channel estimation from one-bit quantized pilot measurements, and propose a novel optimization objective function that attempts to maximize the correlation between the received signal and the generator's channel estimate while minimizing the rank of the channel estimate. Our approach significantly outperforms …
2019

Inverting deep generative models, one layer at a time
Qi Lei, Ajil Jalal, Inderjit Dhillon, Alex Dimakis
Thirty-Third Conference on Neural Information Processing Systems (NeurIPS) 2019
We study the problem of inverting a deep generative model with ReLU activations. Inversion corresponds to finding a latent code vector that explains observed measurements as much as possible. In most prior works this is performed by attempting to solve a non-convex optimization problem involving the generator. In this paper we obtain several novel theoretical results for the inversion problem.
2017
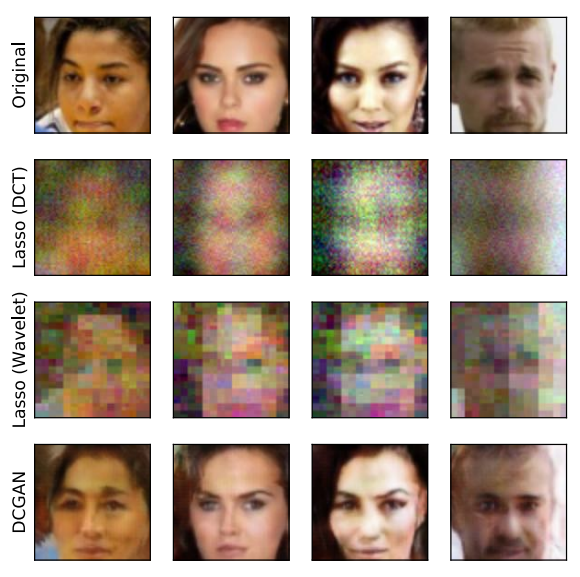
Compressed Sensing using Generative Models
Ashish Bora, Ajil Jalal, Eric Price, Alex Dimakis
International Conference on Machine Learning (ICML) 2017
The goal of compressed sensing is to estimate a vector from an underdetermined system of noisy linear measurements, by making use of prior knowledge on the structure of vectors in the relevant domain. For almost all results in this literature, the structure is represented by sparsity in a well-chosen basis. We show how to achieve guarantees similar to standard compressed sensing but without employing sparsity at all. Instead, we suppose that vectors lie near the range of a generative model $G : \mathbb{R}^k \to \mathbb{R}^n$. Our main theorem is that, if is $L$-Lipschitz, then roughly $O(k \log L)$ random Gaussian measurements suffice for an $\ell_2 /\ell_2$ recovery guarantee. We demonstrate our results using generative models from published variational autoencoder and generative adversarial networks. Our method can use 5-10 x fewer measurements than Lasso for the same accuracy.
2016
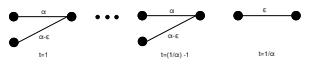
The adwords problem with strict capacity constraints
Umang Bhaskar, Ajil Jalal, Rahul Vaze
Foundations of Software Technology and Theoretical Computer Science (FSTTCS 2016) 2016
We study an online assignment problem where the offline servers have capacities, and the objective is to obtain a maximum-weight assignment of requests that arrive online. The weight of edges incident to any server can be at most the server capacity. Our problem is related to the adwords problem, where the assignment to a server is allowed to exceed its capacity. In many applications, however, server capacities are strict and partially-served requests are of no use, motivating the problem we study. While no deterministic algorithm can be competitive in general for this problem, we give an algorithm with competitive ratio that depends on the ratio of maximum weight of any edge to the capacity of the server it is incident to. If this ratio is 1/2, our algorithm is tight. Further, we give a randomized algorithm that is 6-competitive in expectation for the general problem. Most previous work on the problem and its variants assumes that the edge weights are much smaller than server capacities. Our guarantee, in contrast, does not require any assumptions about job weights. We also give improved lower bounds for both deterministic and randomized algorithms. For the special case of parallel servers, we show that a load-balancing algorithm is tight and near-optimal.